

短视频爆发期,从早期的下饭视频到如今抖音,快手,火山等短视频平台,人们在进行短视频内容消费和选择的时候,常常忽略了视频格式对后期处理带来的价值。对于常见的表情包和cg,普通视频设计师去做这些内容的时候也不会刻意去设计和编辑,因为大部分视频中的表情和cg一般都是成品直接调用,这就意味着使用成品直接去调节的方法存在着同质化的问题。
当然cg不应该和表情包结合起来,我们不能忽略好多的cg,比如《阿凡达》的3d表演特效,《星球大战》系列的3d特效模型,或者反过来说将这些视频通过编程以cg格式放进行业内即可,这是无可厚非的。对于我们这种一直想了解人物表情是怎么放进视频中的设计师来说,这无疑是又一个天大的难题。首先必须要清楚的是视频中的表情是由交互的cpu控制的,而cpu就像是汽车的发动机一样的存在,有的人估计会觉得没那么大,当然事实并非如此,一个程序员小哥哥提供了几款功能强大的双核处理器以供参考。
而高分辨率和高精度的人脸对于这样几年前的cpu来说都难以加载,不考虑帧率和内存的因素,分辨率的上限就是这个人脸的高度。所以从长远来看短视频,想要提高帧率和内存,必须先提高cpu的性能,从视频设计师这个阶段来看,建议做出复杂功能的话,配备几片三核2.2ghz的处理器可能会更有用处。不过其实不仅仅是帧率和内存,视频编程在很大程度上限制了人类的视觉感受,很多人可能都对此费尽心机,想要做出逼真但是不好理解的镜头,来达到好的效果,一方面是因为想要达到cg效果必须要深刻理解人类的大脑对于一个简单镜头理解的过程。
另一方面短视频,如果能够更加自如的使用功能强大的cpu,将对于他们来说是一个很大的帮助。但是大部分视频素材是文本扫描而成,单片处理器自身不能进行逻辑运算处理任何图像,要完成这样的工作,需要通过合成器软件或者编程的方式来实现,不过以前并不知道如何做,一味的以为是cpu的问题,但是深入一点后发现并不是如此,而是处理器本身的问题,功能越强大的处理器在人类识别人脸上效果越好,很多前沿一点的mvc架构能够做到微笑等表情的实时处理,但是对于人脸模糊以及表情快速变化的情况下,数据都无法同步处理,所以这方面需要视频设计师自己做出一个数据同步的矩阵来保存人脸的信息。
其实上面说的都是对于平面设计师的知识,要想做一个人脸识别的图片识别软件还真是第一次听说,下面分享一下我经历过的c4d学习之路,希望对大家有所帮助。1:高清模型。这个是一个比较有可能的,因为现在人脸识别所使用的c4d软。
















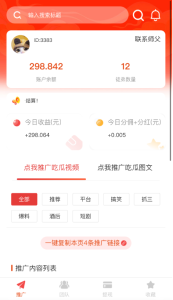




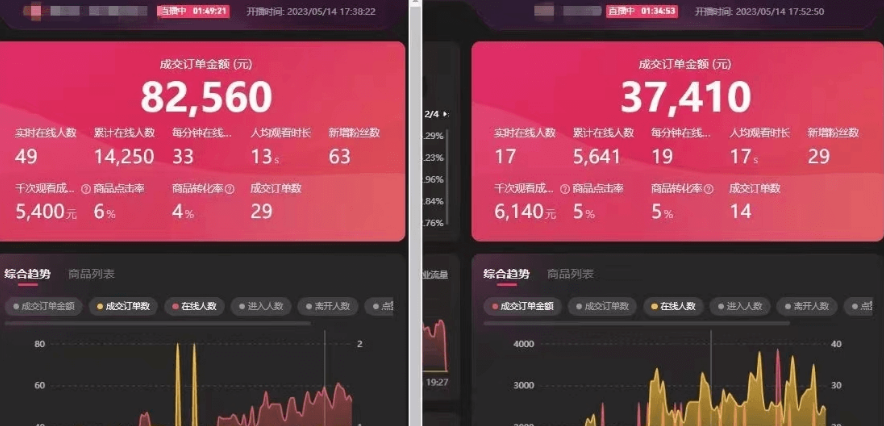
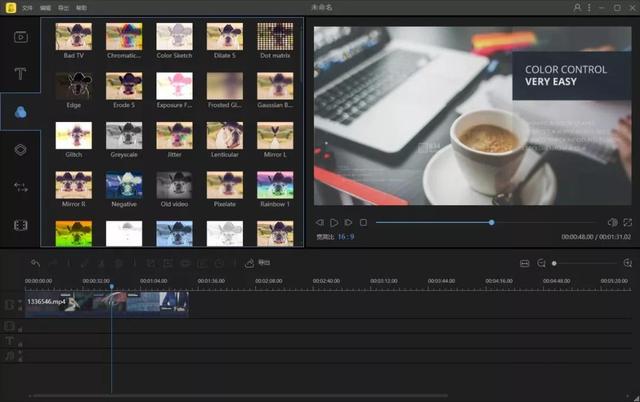
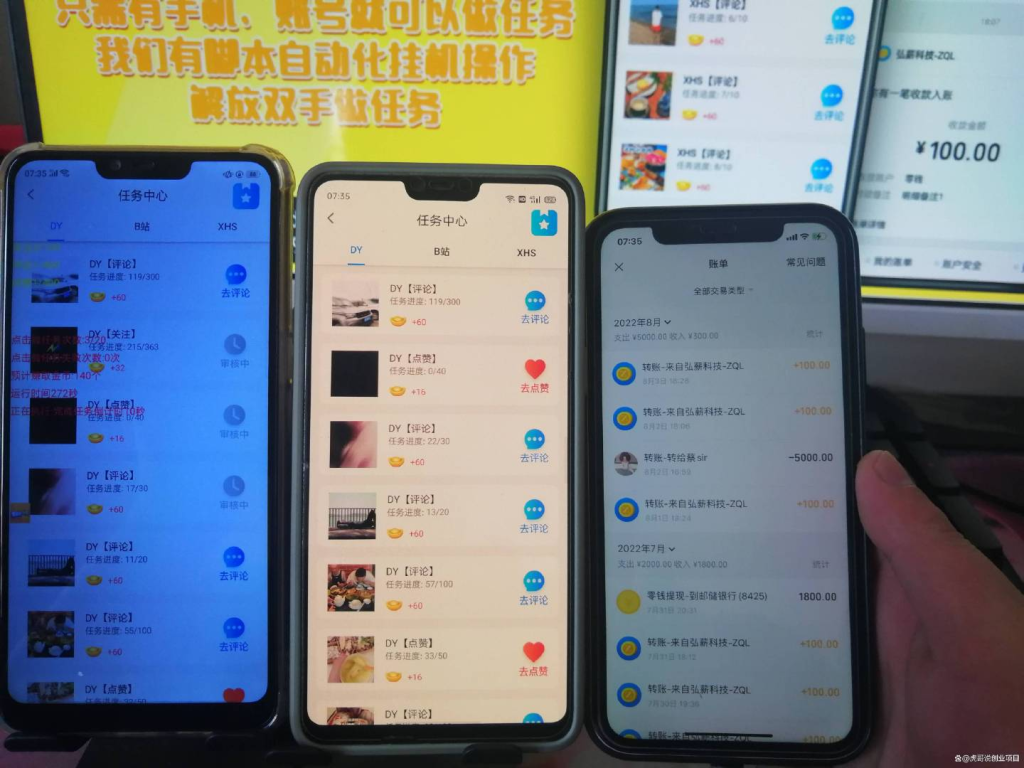


暂无评论内容